Yindjibarndi (Pama-Nyungan)
Yindjibarndi, a language not discussed in our paper, is described by Wordick (1982). Wordick does not posit an inventory containing any complex segments, although fn. 3 on p. 40 suggests that the language may have a series of prenasalized stops: a speaker, when asked to divide multi into syllables, provided mu.nti.
Our corpus is a hand-entered version of each headword provided in Wordick's lexicon; the short version contains all of the 1-2 syllable forms from that lexicon. In both cases, the learner's reaction to the Yindjibarndi data is similar to its reaction to the Quechua word corpus: it unifies all clusters in the data whose frequency is significantly different from 0.
We suspect that two factors lead to this result. First, Yindjibarndi consonantal phonotactics are quite restrictive: clusters appear only between vowels, and are limited in their composition (see Wordick). Second, Wordick's lexicon is small and includes a large number of morphologically complex forms. Unfortunately it is not easy to see whether or not the results would change given a different corpus, because Wordick's lexicon is the only one that we are aware of. Yindjibarndi thus stands as a difficult case for our learner.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| All | LearningData.txt | Features.txt |
| Short | LearningData.txt | Features.txt |
Simulation details for Yindjibarndi all
Input:
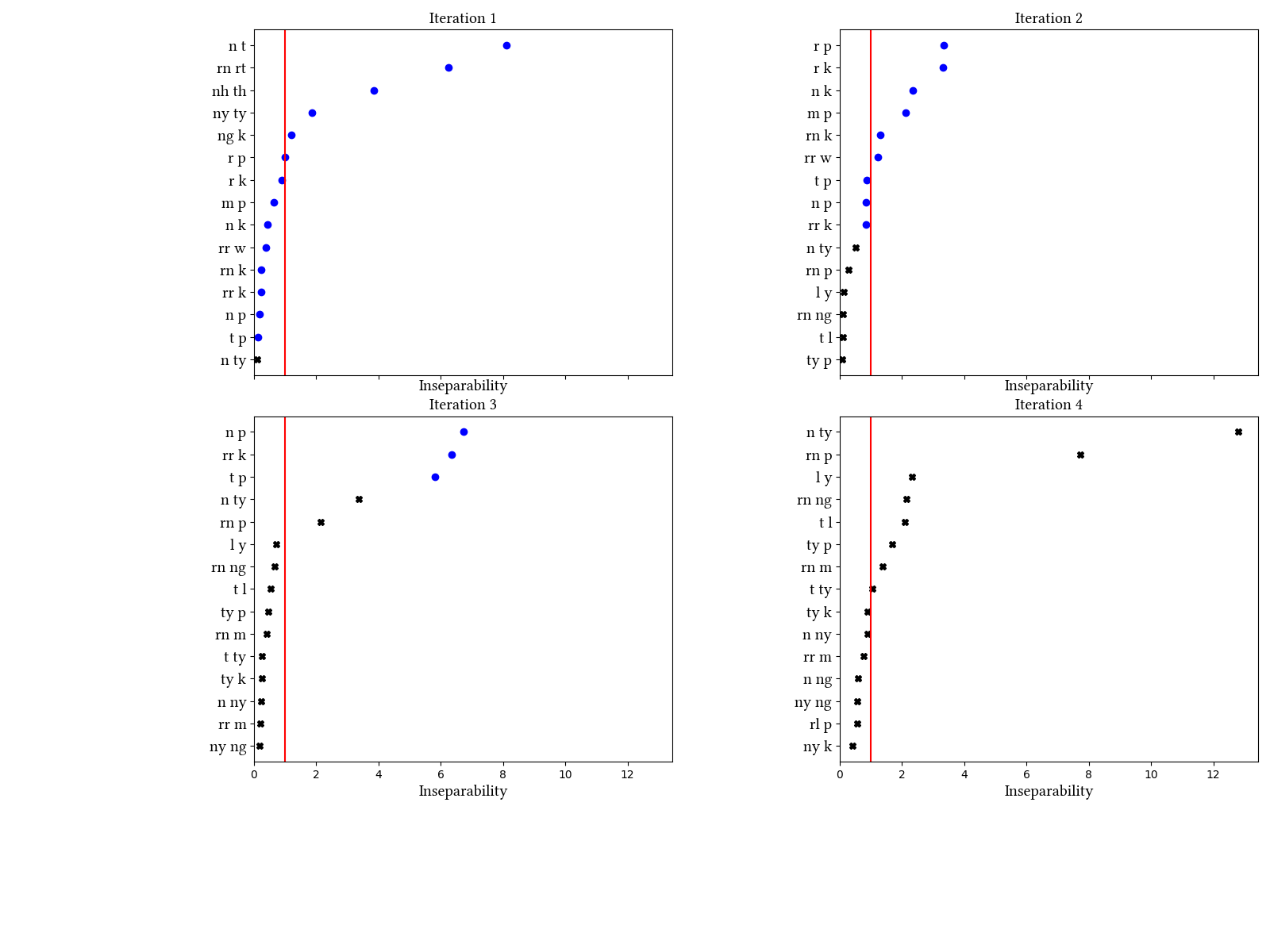
This corpus contains all headwords from Wordick's (1982) lexicon.
LearningData.txt | Features.txt
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
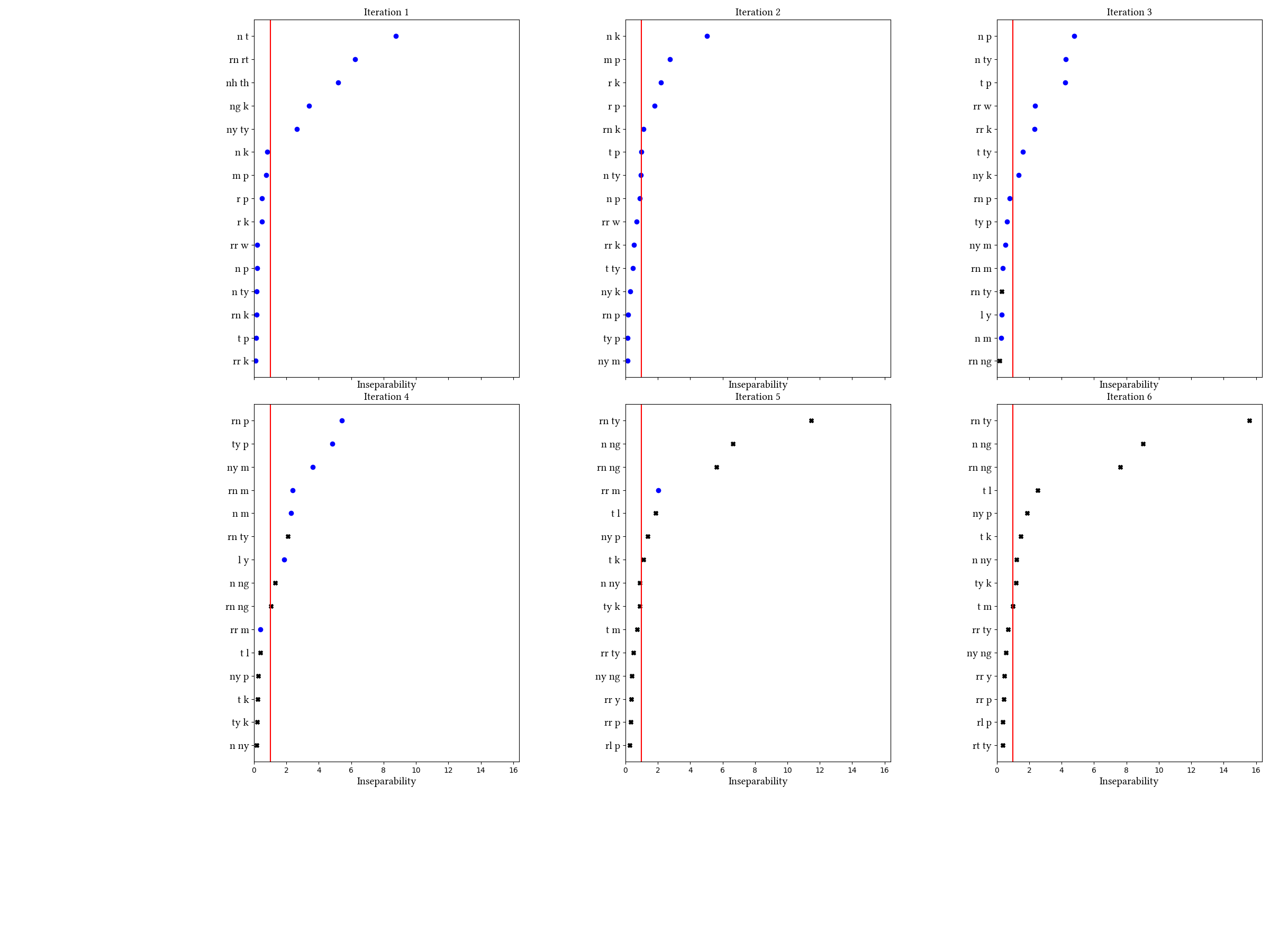
| 1 | LearningData.txt | Features.txt | [download] [view] | ngk, nhth, nyty, nt, rnrt | None |
| 2 | LearningData.txt | Features.txt | [download] [view] | mp, nk, rnk, rp, rk | None |
| 3 | LearningData.txt | Features.txt | [download] [view] | tp, tty, nyk, np, nty, rrk, rrw | None |
| 4 | LearningData.txt | Features.txt | [download] [view] | typ, nym, nm, rnp, rnm, ly | None |
| 5 | LearningData.txt | Features.txt | [download] [view] | rrm | None |
| 6 | No new learning data | No new features | [download] [view] | None | None |