Wolof (Niger-Congo)
Wolof is not mentioned in the paper, but is similar to languages such as Mbay and Ngbaka, in that the arguments for complex segments are relatively straightforward. One of these arguments is distributional: the voiced prenasalized segments can occur in word-initial position (as in mbar 'donkey'), and both the voiced and voiceless series can occur in word-final position (as in bant 'stick', dend 'be next to'). Clusters in Wolof are licit medially (as in marto 'hammer'), but unlike the prenasalized stops, are not permitted in word-initial or word-final position. (These examples, as well as our broader understanding of Wolof phonology, come from Ka 1994.)
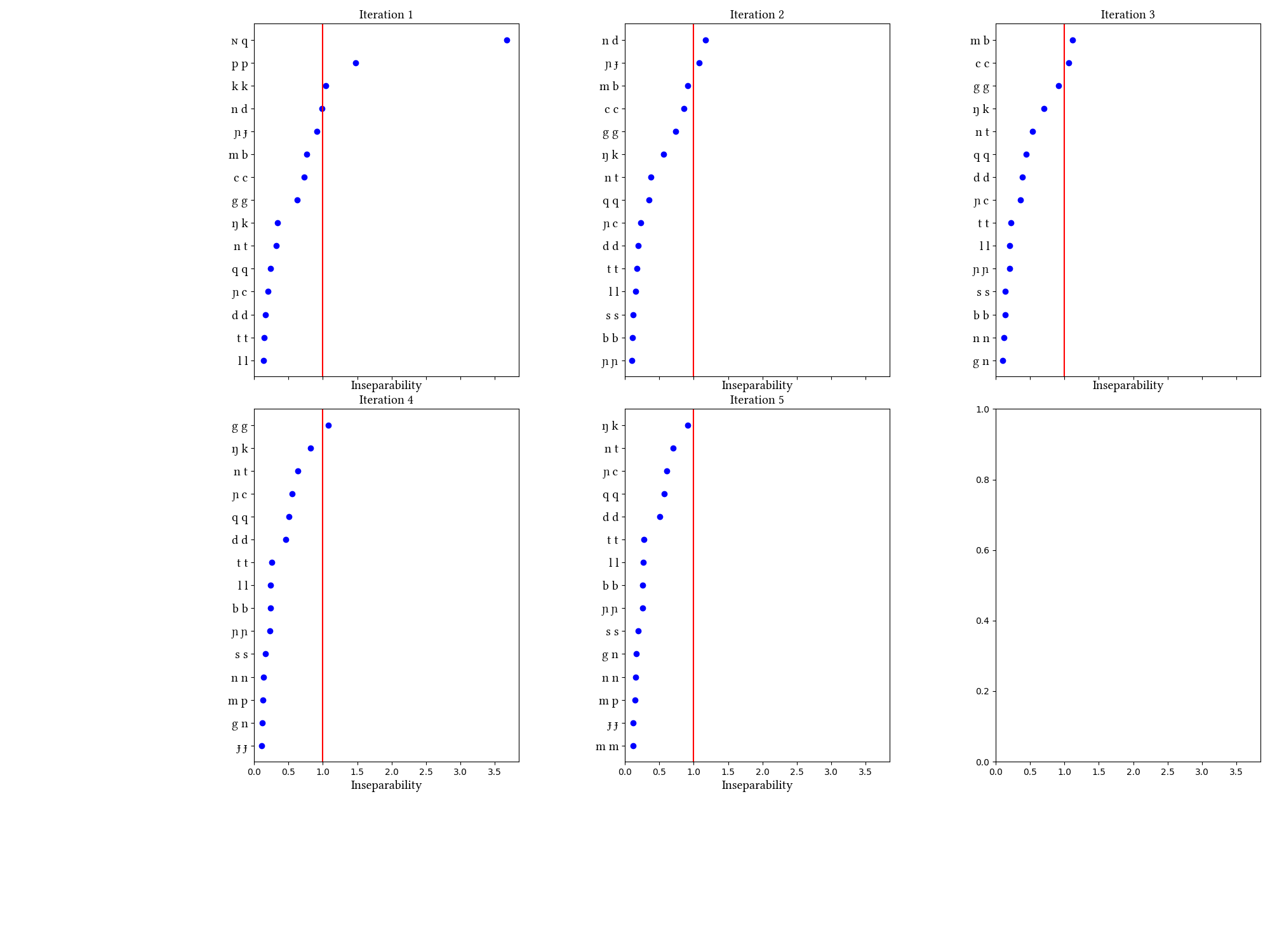
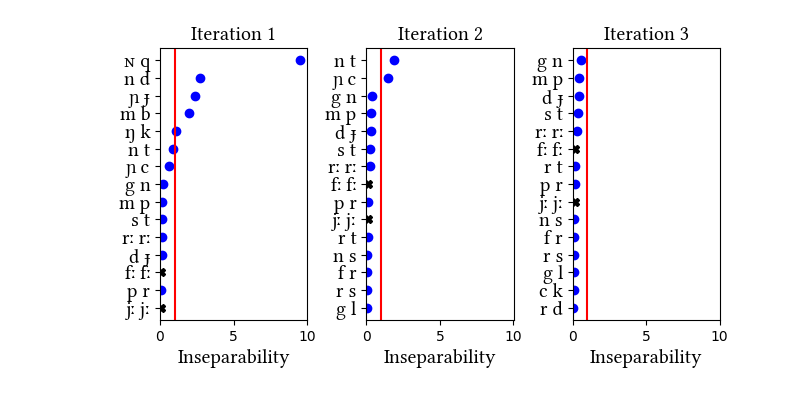
Our Wolof corpus comes from An Crúbadán, which is compiled from online texts. Focusing first on the "Gem" simulation, the learner succeeds in unifying six of the posited prenasalized stops (missing only [ŋg] and [mp]). The "Nogem" simulation assumes an alternative version of the initial state in which geminates are represented in the learner's input as sequences of identical consonants; the learner unifies several of the geminates ([pp kk cc]) as well as a subset of the prenasalized stops.
One possible explanation of this learner's failure to consistently unify geminates is that they are not represented as sequences of segments in the initial state; geminates, unlike complex segments, do not result from a process of unification. It is less clear why the learner fails to unify [mp] and [ŋg], but it is possible that its failure in this domain is due to aspects of the corpus: the An Crúbadán corpus for Wolof contains a large number of French words, which have not been filtered out. Further work is necessary to determine what the results would look like with a more carefully curated corpus.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Nogem | LearningData.txt | Features.txt |
| Gem | LearningData.txt | Features.txt |
Simulation details for Wolof nogem
Input:
This version of the learning data assumes that geminates are represented as a sequence of identical consonants in the initial state. (Note that all vowels are transcribed as "v", making this corpus useful for the investigation of consonant distribution only.)
LearningData.txt | Features.txt
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | pp, kk, ɴq | ɴ |
| 2 | LearningData.txt | Features.txt | [download] [view] | nd, ɲɟ | None |
| 3 | LearningData.txt | Features.txt | [download] [view] | cc, mb | None |
| 4 | LearningData.txt | Features.txt | [download] [view] | gg | None |
| 5 | No new learning data | No new features | [download] [view] | None | None |