Sundanese (Austronesian)
Sundanese is discussed in the paper in its own section. It is unique among our case studies in that the learner finds a larger inventory of complex segments than has been posited by analysts.
The corpus for Sundanese is Lembaga Basa & Sastra Sunda's (1985) monolingual Sundanese dictionary, which comprises 13,405 distinct lexical entries (a further 2,923 are explicitly marked as loanwords; we ran simulations with and without them. They are excluded from the simulation we report in the paper). The dictionary was hand-entered into a text file.
Despite claims by some (e.g. Blust 1997:160) that Sundanese has a series of prenasalized stops, the descriptive work that we are aware of (Cohn 1992; Robins 1957, 1959) does not characterize them in this way, and Cohn & Riehl (2016) argue (on the basis of phonetic and phonological criteria) that they are best-treated as clusters. Our learner's predictions regarding the segmental inventory of Sundanese thus diverge from claims the of traditional analysts. Without information about the intuitions of native Sundanese speakers, is difficult to determine which analysis is correct.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| With_Loans | LearningData.txt | Features.txt |
| Without_Loans | LearningData.txt | Features.txt |
Simulation details for Sundanese with_loans
Input:
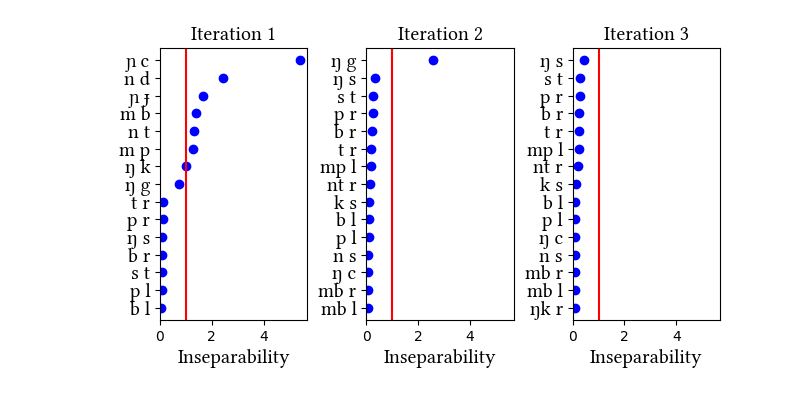
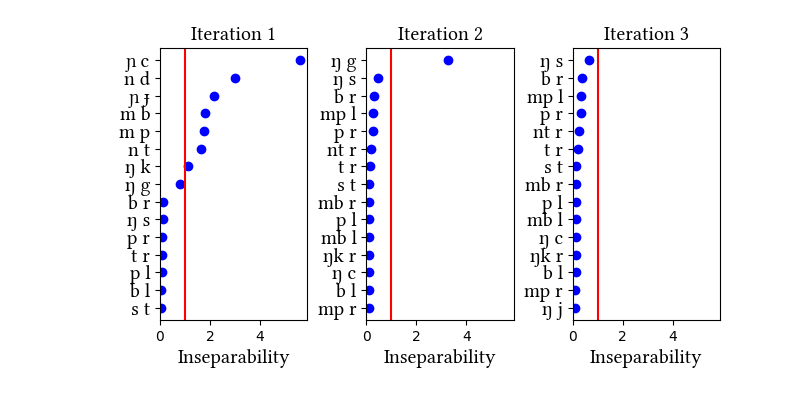
The dictionary we used explicitly marks loanwords; these are included in this version of the data. As you can see, the simulation results are qualitatively the same whether loanwords are included or not, but the simulation with loanwords takes more iterations to arrive at the same inventory.
LearningData.txt | Features.txt
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | mb, mp, nd, nt, ɲɟ, ɲc, ŋk | None |
| 2 | LearningData.txt | Features.txt | [download] [view] | ŋg | None |
| 3 | No new learning data | No new features | [download] [view] | None | None |