Mexican Spanish (Indo-European)
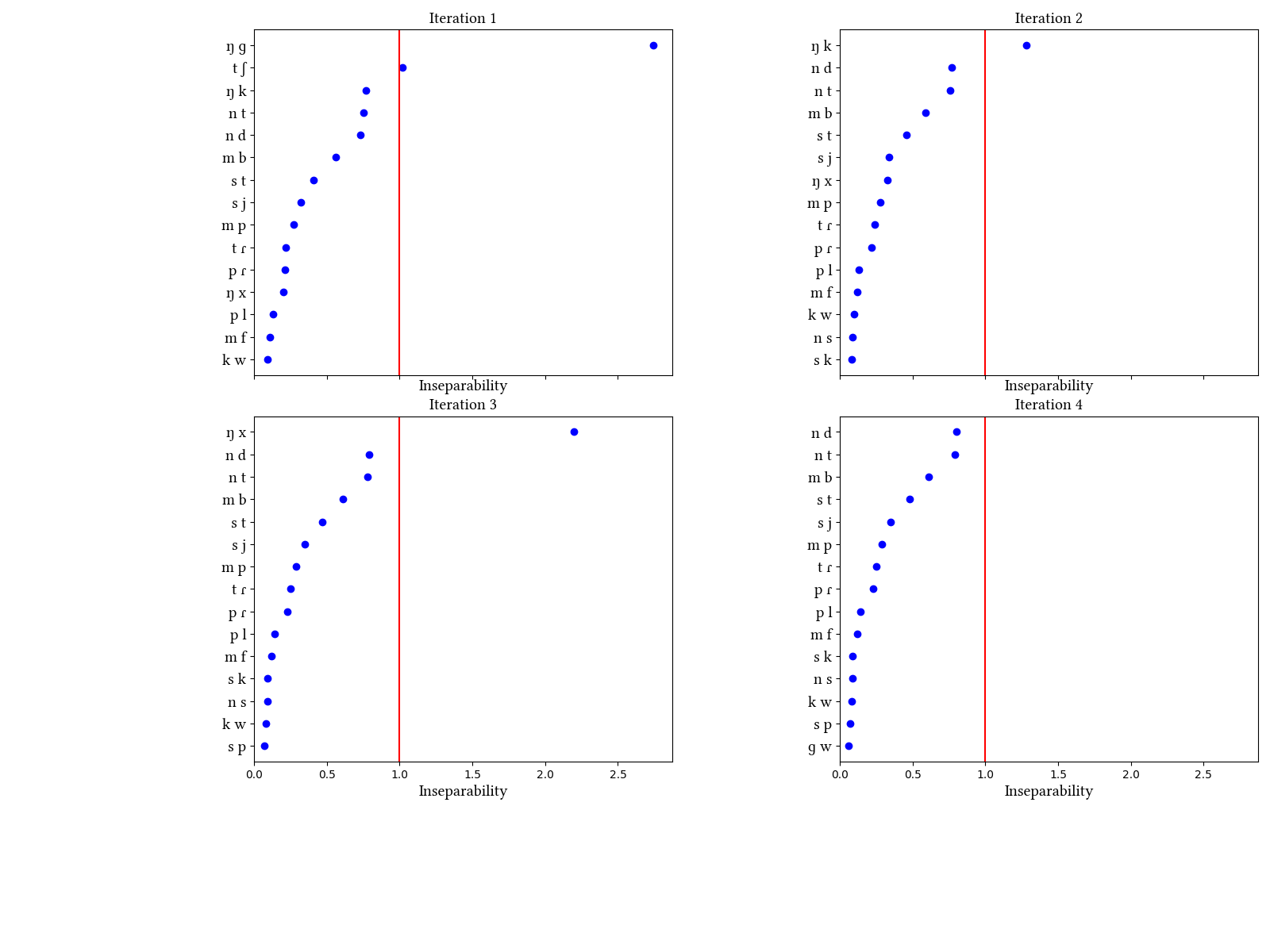
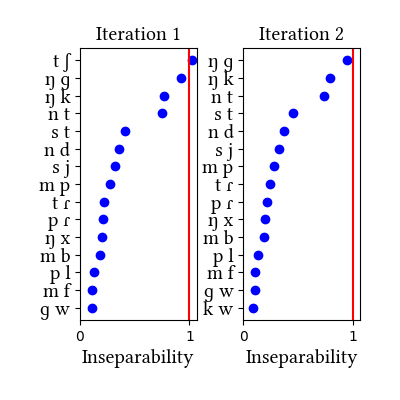
Spanish is not in the paper. This pair of simulations shows how big a difference transcriptions can make. While the learner has no difficulty identifying the uncontroversial affricate of Spanish, [tʃ], it also sometimes finds other things, depending on how the data are transcribed. The dataset comes from this site and was converted into IPA according to descriptions of (approximately) Mexican Spanish. There are two versions of the data: one reflects the complementary distribution of [β ð ɣ] and [b d g], and the other transcribes all voiced obstruents as [b d g]. In the "narrow transcription" version, with spirants, the voiced stops occur predominantly after homorganic nasals, and so the learner unifies them into prenasalized stops. As a side effect, it unifies [ŋ k] and [ŋ x]. In the "broad transcription" version, the voiced stops have a more diverse distribution and a more separable from their nasals. Thus, the fact that [ŋ] occurs only in [ŋ ɡ, ŋ k, ŋ x] is no longer an issue, and it is not unified with these consonants.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Narrow | LearningData.txt | Features.txt |
| Broad | LearningData.txt | Features.txt |
Simulation details for Spanish narrow
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | tʃ, ŋɡ | ʃ |
| 2 | LearningData.txt | Features.txt | [download] [view] | ŋk | None |
| 3 | LearningData.txt | Features.txt | [download] [view] | ŋx | ŋ |
| 4 | No new learning data | No new features | [download] [view] | None | None |