Standard Russian (Indo-European)
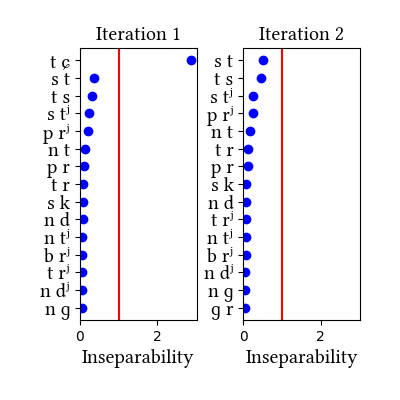
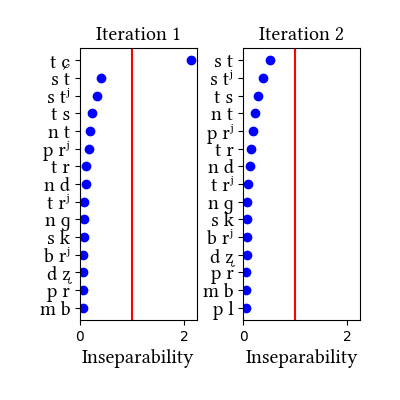
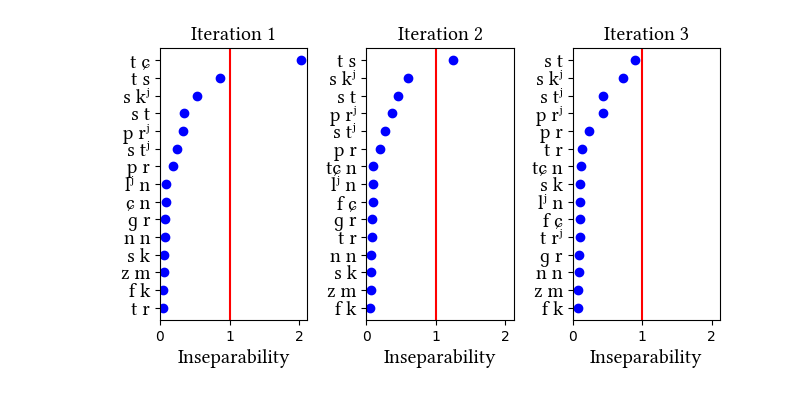
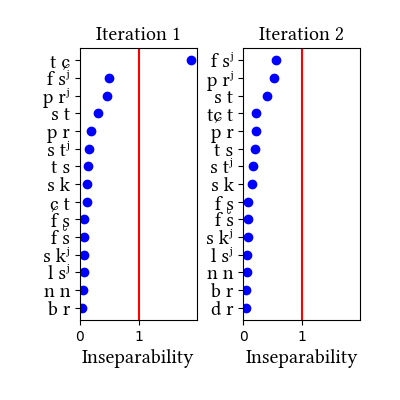
Russian has its own section in the paper, as an example of a language where clear phonotactic arguments for affricates are lacking but statistical distributions are informative. Russian affricates are etymologically derived from dorsal and coronal stops, and they are quite frequent in the language--so much so that the learner identifies them without narrow transcriptions. While we discuss the two dictionary simulations in the paper, we also tried a simulation on a different data set: a kind of mock-up of a transcribed connected speech corpus. It was created by transcribing a bunch of Russian novels and removing the word boundaries. The main lesson we learn from this exercise is that the learner is sensitive to the type/token frequency distinction--it does not learn the same inventories when trained on words vs. connected speech. But we do not know which of the simulations produces the "right" result, since we do not know which representations the Russian speakers have for these sounds.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Morphemes | LearningData.txt | Features.txt |
| Stems | LearningData.txt | Features.txt |
| Zaliznjak | LearningData.txt | Features.txt |
| Novel_Corpus | LearningData.txt | Features.txt |
| Tikhonov | LearningData.txt | Features.txt |
Simulation details for Russian morphemes
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
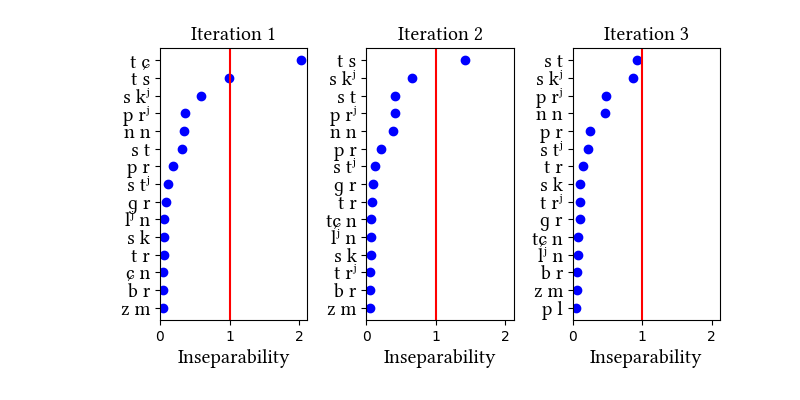
| 1 | LearningData.txt | Features.txt | [download] [view] | tɕ | ɣ, ʑ |
| 2 | No new learning data | No new features | [download] [view] | None | None |