Ngbaka (Niger-Congo)
The Ngbaka simulation is described in the paper.
The corpus is from Henrix's (2015) Ngbaka-French dictionary and comprises 5,571 distinct lexical items. The dictionary was hand-entered into a text file; tones are not transcribed, but lexical items differing in tone alone are not collapsed into a single entry. Further description of the language can be found at the beginning of Maes's (1959) dictionary.
Note that the variety of Ngbaka discussed and analyzed in this paper is distinct from Ngbaka Ma'bo, the language described by Thomas (1963) and analyzed by Sagey (1986) (among many others). For more information on the relationship between these two languages, see Danis (2017:51-53).
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| only version | LearningData.txt | Features.txt |
Simulation details for Ngbaka
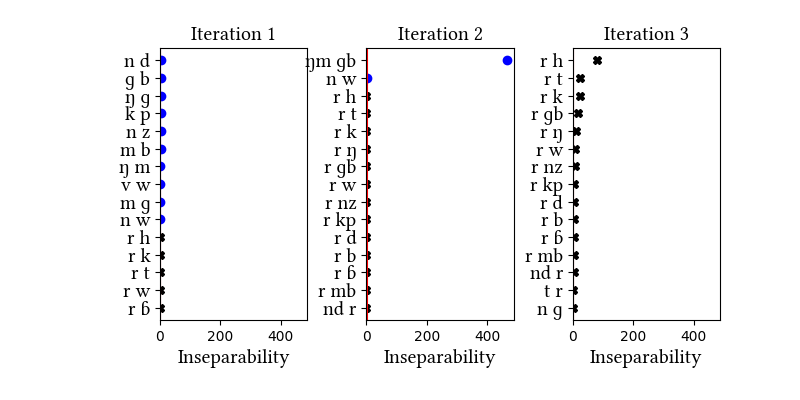
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | kp, ɡb, mb, nd, nz, ŋɡ, ŋm, vw | None |
| 2 | LearningData.txt | Features.txt | [download] [view] | nw, ŋmɡb | None |
| 3 | No new learning data | No new features | [download] [view] | None | None |