Navajo (Athabaskan)
Navajo is mentioned in our paper in passing in the discussion of the nature of the learning data. We wanted to look at the language because it has a large inventory of affricates, both strident and non-strident, with laryngeal contrasts. The inevitable frequency differences between these sounds make it a tricky case for our learner, and indeed the results vary depending on the dataset we use. The learner comes the closest to the traditional phonological analyses of Navajo (e.g., Harry Hoijer's) when trained on the most curated dataset is the roots/stems list.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Stems | LearningData.txt | Features.txt |
| Web_Words | LearningData.txt | Features.txt |
| Young_Morgan_Dictionary | LearningData.txt | Features.txt |
Simulation details for Navajo stems
Input:
This data set was prepared by Gillian Gallagher on the basis of a stem list provided by David Eddington.
LearningData.txt | Features.txt
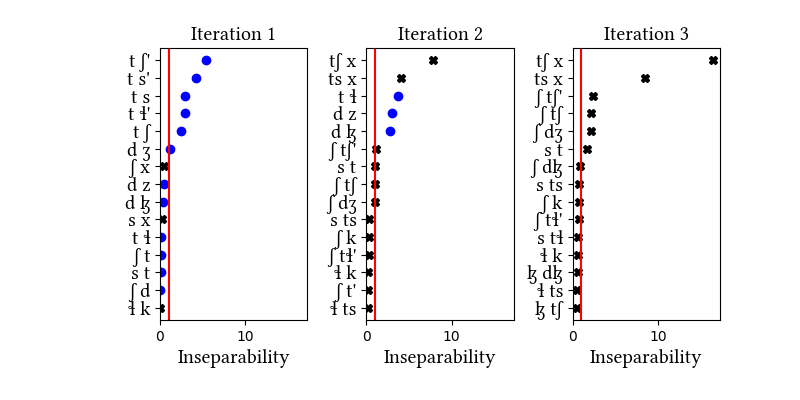
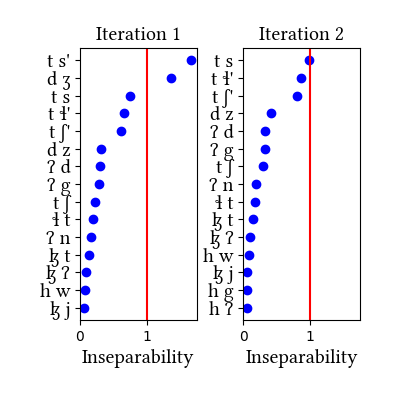
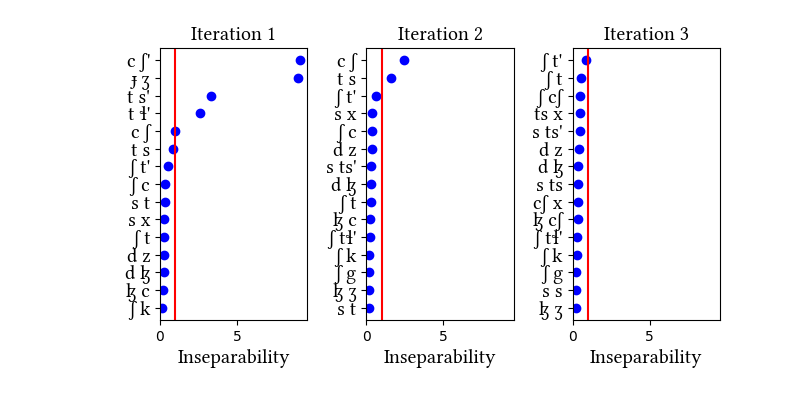
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | dʒ, tʃ', ts', tɬ', ts, tʃ | ɟ, p, c, ʃ', s', ɬ' |
| 2 | LearningData.txt | Features.txt | [download] [view] | dɮ, dz, tɬ | None |
| 3 | No new learning data | No new features | [download] [view] | None | None |