Khalkha Mongolian (Mongolic)
Mongolian is not in the paper. The language is described by Svantesson et al. (2005, Phonology of Mongolian) as having the affricates [ts], [tsʰ], [tʃ], [tʃʰ]. It furthermore has a palatalization and an aspiration contrast for most of its obstruents, neither of which we not tackle here.
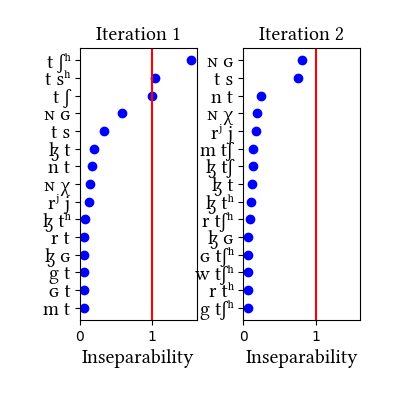
The learner was trained on an An Crúbadán corpus, transcribed from Cyrillic according to Svantesson et al. (See here). The learner does pretty well on this corpus, even though it is not the best data source: it identifies all affricates but the plain [ts].
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| only version | LearningData.txt | Features.txt |
Simulation details for Mongolian
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | tʃʰ, tsʰ, tʃ | None |
| 2 | No new learning data | No new features | [download] [view] | None | None |