Standard Hungarian (Uralic)
Hungarian is analyzed as having the alveolar and postalveolar/palatal affricates in Siptár and Törkenczy's (2000) book, Phonology of Hungarian. The arguments, we think, are not super clear, since Hungarian is fairly permissive phonotactically. There are stop-fricative sequences in the language, and while they are etymologically foreign, they can occur in the same environments as the purported affricates. The weakness of the arguments is in line with the inconsistent findings of the learner.
The closest the learner comes to the inventory posited by traditional analyses of the langugae is when it is trained on the list of stems/roots. This could be due to the agglutinative morphology of the language; the clusters found in morphologically complex words are more diverse than those in morphemes, so the affricates' share of the distribution is lower in words than in morphemes.
Simulation data at a glance
Click on simulation name to view additional simulation details.
Simulation details for Hungarian words broad
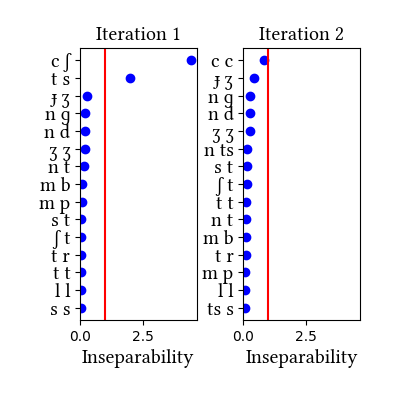
The simulation trained on the broadly transcribed words does not find any complex segments at all.
Input:
This dataset was prepared by Ildi Emese Szabó from the Szótár AdatBázis 1.0 dictionary. The process of cleaning and transcribing is described here. This version of the dataset is transcribed with alveolar symbols for the affricates [tʃ] and [dʒ].
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|
| 1 |
No new learning data |
No new features |
[download] [view] |
None |
None |
Summary of inventory changes
| Stage | Consonant set |
|---|
| Input | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː vː sː zː ʃː ʒː hː mː nː ɲː lː rː jː |
| Output | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː vː sː zː ʃː ʒː hː mː nː ɲː lː rː jː |
Simulation Plots
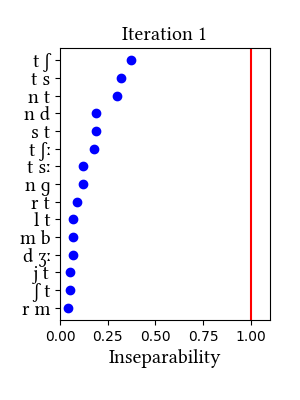
Simulation details for Hungarian words narrow
The narrow transcriptions allow the learner to find the postalveolar voiceless affricates but nothing else. In particular, [ts] is well below the threshold. This could be because morphological complexity dilutes the frequency of affricates, as it does in Quechua (see the discussion in the paper).
Input:
Data prepared by Ildi Emese Szabó from the Szótár AdatBázis 1.0 dictionary (Details here). Apart from substituting affricate symbols with corresponding stop-fricative symbols, this version of the data has narrow allophones for the stop portions of postalveolars--transcribed as [cʃ] and [ɟʒ].
Summary of iterations:
Summary of inventory changes
| Stage | Consonant set |
|---|
| Input | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː vː sː zː ʃː ʒː hː mː nː ɲː lː rː jː |
| Output | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː vː sː zː ʃː ʒː hː mː nː ɲː lː rː jː cʃ cʃː |
Simulation Plots
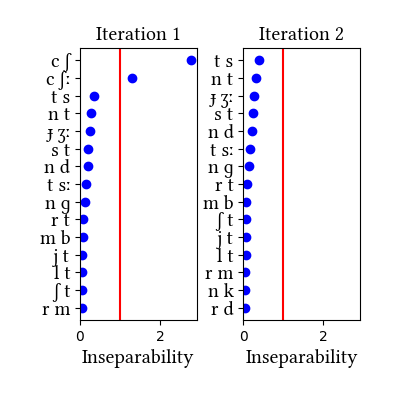
Simulation details for Hungarian roots
The simulation run on roots finds the less controversial affricates of Hungarian, [ts] and [tʃ], even without resorting to narrow transcription of the latter. The more controversial affricate [dʒ] just misses the threshold on the 2nd iteration. See Siptár and Törkenczy's discussion in their section 4.1.4, where they also weigh the arguments for [dz] (nowhere near the threshold for unification in any of our simulatoins for the language).
Input:
Root/stem list prepared by Ildi Emese Szabó from the Szótár AdatBázis 1.0 dictionary (details here). Only the broad transcription of affricates, [tʃ] and [dʒ], was tested in this simulation.
Summary of iterations:
Summary of inventory changes
| Stage | Consonant set |
|---|
| Input | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː vː sː zː ʃː ʒː hː mː nː ɲː lː rː jː |
| Output | p b t d c ɟ k ɡ f v s z ʃ ʒ h m n ɲ l r j pː bː tː dː cː ɟː kː ɡː fː sː zː ʃː ʒː mː nː ɲː lː rː jː ts tʃ |
Simulation Plots
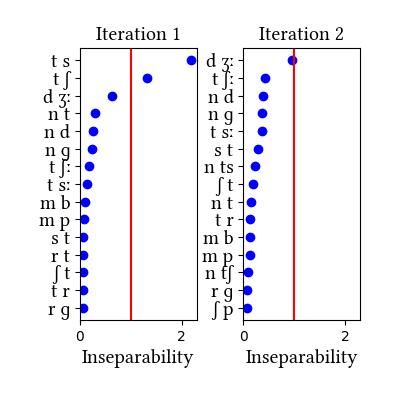
Simulation details for Hungarian gem_rts_narrow
The simulation run on roots finds the less controversial affricates of Hungarian, [ts] and [tʃ], even without resorting to narrow transcription of the latter. The more controversial affricate [dʒ] just misses the threshold on the 2nd iteration. See Siptár and Törkenczy's discussion in their section 4.1.4, where they also weigh the arguments for [dz] (nowhere near the threshold for unification in any of our simulatoins for the language).
Input:
Root/stem list prepared by Ildi Emese Szabó from the Szótár AdatBázis 1.0 dictionary (details here). This version of the data has broad transcriptions for affricates (d, t as first elements even in palatals); it also replaces geminates with two singletons in the initial data set to see if the learner will unify all the geminates into single segments.
Summary of iterations: