Standard German (Indo-European)
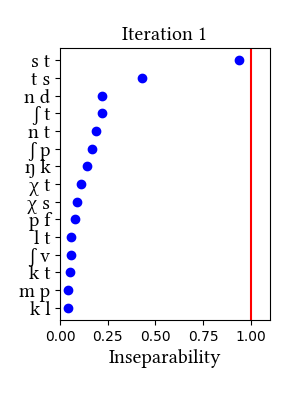
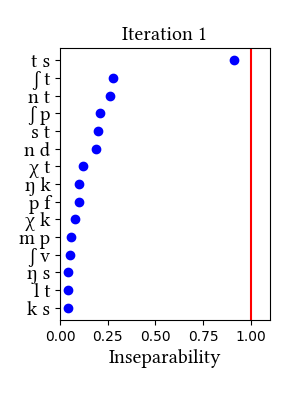
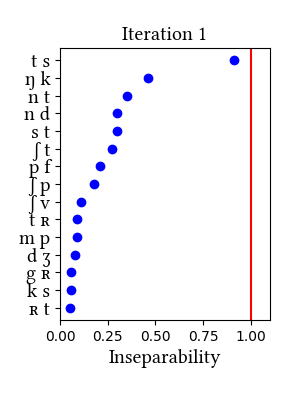
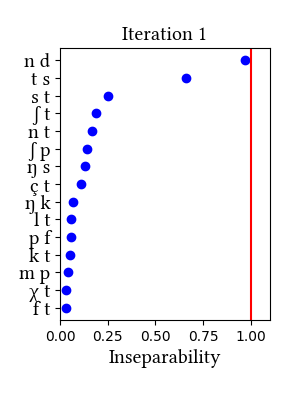
German is not discussed in the paper, but in our taxonomy of case studies, it would fall in the "controversial/unclear" category. As reviewed in Richard Wiese's book (2000, The Phonology of German, Oxford University Press), the analysis of the German consonant inventory has been debated since Trubetzkoy introduced his criteria for complex segments. The two affricates [ts] and [pf] are least controversial; [tʃ] and [dʒ] are more controversial. Wiese himself argues that [ps] and [ks] should be considered affricates, too.
Our learner finds no complex segments in German, although it should be noted that [ts] comes very close to the threshold in the simulation that uses morphemes as learning data. Since neither the arguments nor the results of our simulations are conclusive, we might have to wait for some behavioral/experimental evidence for a better understanding of the phonemic inventory of this well-studied language.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Celex Words | LearningData.txt | Features.txt |
| Celex Lemmas | LearningData.txt | Features.txt |
| Celex Morphemes | LearningData.txt | Features.txt |
| Schott | LearningData.txt | Features.txt |
Simulation details for German celex words
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | No new learning data | No new features | [download] [view] | None | None |