European / Quebecois French (Indo-European)
European French is traditionally analyzed as having no complex segments, even though it is phonotactically fairly permissive, and allows [tʃ] in word-initial position (alongside [ps], [ks] and other stop-fricative clusters).
By contrast, Quebecois French is described as having the affricates [ts] and [dz], which occur before high front vowels [i, y]. This analysis is supported by some experimental evidence (Béland and Kolinsky 2005, Journal of Multilingual Communication Disorders 3:2, pp. 110-117)
We tried the learner on two data sources: a large corpus of child-directed speech, and the Lexique dictionary of French (where 71K words have transcriptions). We transcribed both datasets as either European French (unmodified transcriptions from Lexique and CHILDES) or as having the affrication rule (replacing t/d with ts/dz before {i, y}). Our learner finds the affricates in the CHILDES corpus, which represents token frequencies in connected speech. Training the learner on the Lexique transcribed as Quebecois does not bring the learner to threshold, although [d z] and [t s] are the most inseparable clusters in the data. (The same result obtains when we train the learner on CHILDES tokenized by word; no complex segments are found.)
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Quebec Lexique | LearningData.txt | Features.txt |
| Euro Lexique | LearningData.txt | Features.txt |
| Quebec Childes_Cds_Type | LearningData.txt | Features.txt |
| Quebec Childes_Cds_Token | LearningData.txt | Features.txt |
| Euro Childes_Cds_Type | LearningData.txt | Features.txt |
| Euro Childes_Cds_Token | LearningData.txt | Features.txt |
Simulation details for French quebec lexique
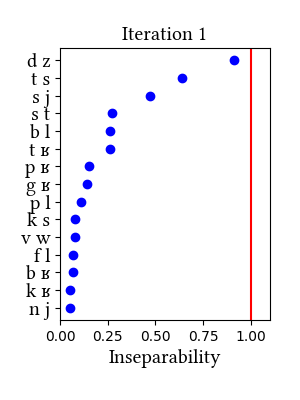
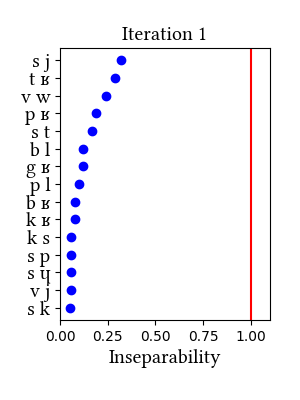
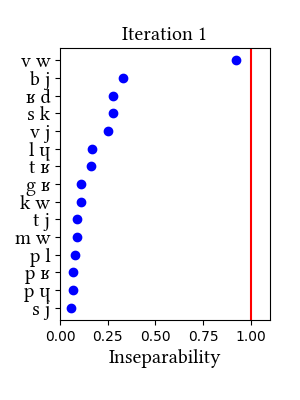
In this simulation, the learner does not unify [ts] and [dz], but they are at the top in terms of inseparability scores (dz = 0.91, ts = 0.64).Input:
This dataset is Lexique, with {t, d} replaced by corresponding affricates {t s}, {d z} before {y/i}.
LearningData.txt | Features.txt
Summary of iterations:
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | No new learning data | No new features | [download] [view] | None | None |