Boumaa Fijian (Austronesian)
The Fijian simulation is described in detail in the early sections of the paper.
The corpus is from An Crúbadán, which is compiled from online texts. There are quite a few English words in the data so they were eliminated by intersecting the corpus with Celex, and by removing any remaining words that had non-Fijian orthographic consonant clusters. See here for more.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| only version | LearningData.txt | Features.txt |
Simulation details for Fijian
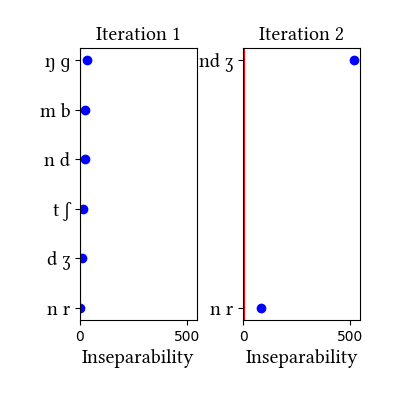
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | tʃ, mb, nd, ŋɡ | b, d, ɡ, ʃ |
| 2 | LearningData.txt | Features.txt | [download] [view] | nr, ndʒ | ʒ |