American English (Indo-European)
English is discussed in its own section in the paper, which reviews the arguments for its two purported affricates and discusses the data sources we used. Briefly, the arguments are not particularly strong, and the results of our simulations are correspondingly fragile. Finding [tʃ] requires narrow transcription of the stop portion. While this can be motivated, it is not necessary in other cases.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Celex Broad | LearningData.txt | Features.txt |
| Cmu Narrow | LearningData.txt | Features.txt |
| Celex Narrow | LearningData.txt | Features.txt |
| Cmu Broad | LearningData.txt | Features.txt |
Simulation details for English celex broad
Input:
Data source: Celex lemmas. The Celex transcriptions assume British English pronunciations.
LearningData.txt | Features.txt
Summary of iterations:
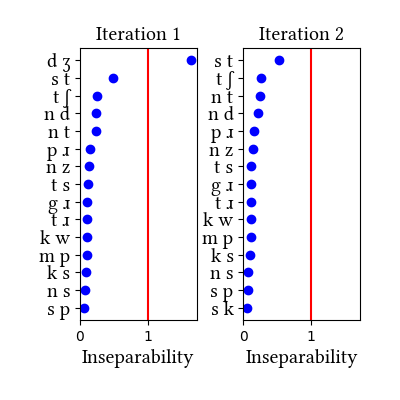
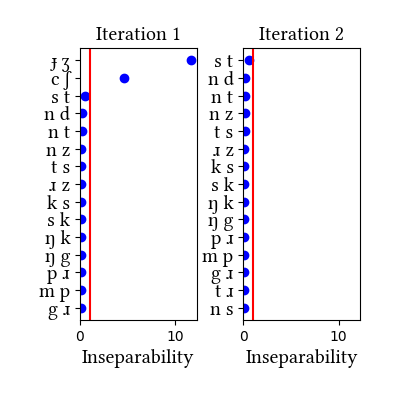
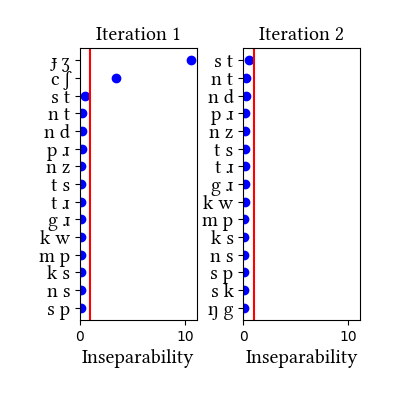
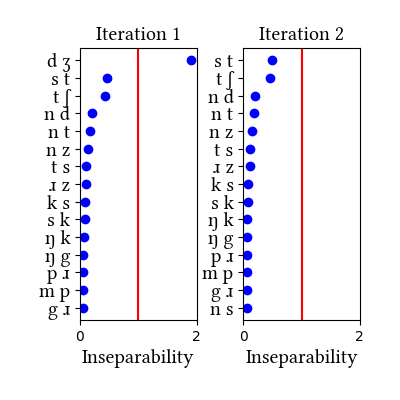
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | dʒ | None |
| 2 | No new learning data | No new features | [download] [view] | None | None |