Bolivian Aymara (Aymaran)
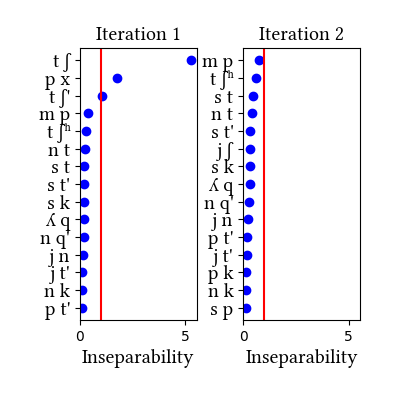
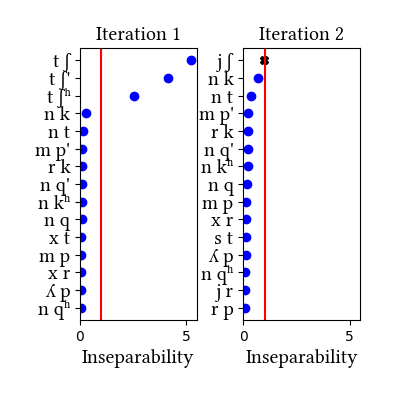
Aymara is not discussed in the paper. This case is interesting in that Aymara shares many features in common with Quechua, but the case study works out rather differently because of the differences between the languages' phonotactics and morphology. Like Quechua, Aymara is normally analyzed as having affricates in its stop inventory: [tʃ, tʃʰ, tʃ']. The arguments for their inclusion are exactly parallel to the ones in Quechua. But Aymara differs from Quechua in one key respect: it has a rule of vowel deletion at morpheme boundaries, which creates many derived consonant clusters. This rule enriches the inventory of consonant clusters so much that the learner "misfires" only slightly in Aymara when trained on words: it finds [px], a cluster that occurs only at morpheme boundaries, and it fails to find [tʃʰ], a sequence that is too separable in the data (even though there is no aspirated ʃ́ʰ in the language). The learner succeeds in identifying all and only the complex segments posited for Aymara when trained on roots, just as it does in Quechua. The data come from Gouskova and Gallagher (2019, NLLT) and Gallagher et al. (2019, Glossa); the only change we made is to modify the feature set and to convert the data into IPA.
Simulation data at a glance
Click on simulation name to view additional simulation details.
| Simulation name | Initial state Learning Data | Initial state features |
|---|---|---|
| Words | LearningData.txt | Features.txt |
| Roots | LearningData.txt | Features.txt |
Simulation details for Aymara words
| Iteration | Learning Data produced | Features produced | Inseparability | New Segments added | Segments removed |
|---|---|---|---|---|---|
| 1 | LearningData.txt | Features.txt | [download] [view] | px, tʃ', tʃ | ʃ' |
| 2 | No new learning data | No new features | [download] [view] | None | None |